https://toss.im/slash-21/sessions/2-1
토스 데이터의 흐름과 활용
토스의 데이터 흐름과 활용 방법, 그리고 용도에 따라 어떤 플랫폼을 활용하는지를 공유합니다.
toss.im
(유튜브에 올라온 강의와 해당 링크의 발표 자료를 보고 정리한 내용)
유결_Data Platform Team Leader
머신러닝 파이프라인, 서비스를 위한 데이터기반 API 서버 개발 등에 기여하는 데이터 플랫폼 팀

1. 데이터 정의: 테이블 및 로그 정의
데이터를 올바르게 수집되도록 잘 정의하는 것.
Silo: 토스 앞쪽에서 각 서비스를 만들고 운영
중앙 데이터플랫폼 팀
SDK로 필요한 로그 심음.
log centre: 로그 정의 및 검색 관리 툴
- 화면 로그 및 이벤트 정의
- 유니크한 스키마 ID를 갖게 됨
* 로그란?
어떤 시스템, 애플리케이션, 프로세스에서 발생하는 이벤트나 활동을 시간순으로 기록한 데이터
- 시스템 동작 모니터링
- 문제 추적/분석하는 정보 제공
- 이벤트 중심 데이터 e.g. 사용자 로그인, 파일 다운로드, 서버 오류 등
- structured/un-structured data: 구조화된 데이터(JSON, XML 형태)로 저장 / 비구조화된 텍스트(평문) 형태로 저장
목적
- debugging
- 보안 모니터링
- 성능 분석
- 사용자 행동 분석
로그센터에 정의된 스키마와 valid
로그 이상에 있을 때 slack으로
2.1. 데이터 수집 및 저장 : DB 데이터 입수
mySQL DB -> Scoop 으로 적재
HDFS -> batch centre 을 통해 적재
2.2. 데이터 수집 및 저장: 로그 데이터 입수
Kafka로 적재된 로그 -> HBase Kudu, HDFS 등에 적재됨

Toss Datahub 자체 개발
- 아 되게.. 자체개발한 게 엄청 많네?? 흠냐링
Hadoop이 뭘까?
*HDFS
Hadoop Distributed File System
Hadoop 프레임워크의 핵심 파일 시스템
- 대규모 데이터를 분산하여 저장
- 고가용성을 보장
대용량 데이터를 처리하기 위해 설계됨. 분산 환경에서 데이터를 효율적으로 저장하고 관리
특징
- 분산 저장: 여러 노드에 분산 저장하여 시스템 전체 용량을 활용
- Fault Tolerance (내결합성): 데이터를 여러 replica 로 저장하여 노드나 디스크 장애 발생 시에 데이터 손실 방지
- 대용량 데이터 처리: TB, PB 규모의 데이터 처리 가능
- 스트리밍 데이터 접근: 읽기 중심의 처리에 적합
- 큰 파일 처리
* Hadoop
오픈소스 분산 데이터 처리 프레임워크
Apache Software Foundation에서 개발 및 관리
주요 구성 요소
- HDFS
- MapReduce: 데이터 처리 모델, 대규모 데이터를 병렬로 처리 (Map 단계, Reduce 단계)
- YARN (Yet Another Resource Negotiator): 클러스터에서 자원 관리, 애플리케이션 실행을 조정하는 리소스 관리 프레임워크
- Hadoop Common: HDFS, YARN, MapReduce에서 공통적으로 사용하는 라이브러리와 유틸리티 포함
-> Hadoop과 HDFS에서 데이터 저장 / 데이터 분석(사용자 행동 분석, 추천 시스템, 마케팅 캠페인 등) / 빅데이터 처리 / 머신러닝과 AI 로 활용
- Heterogeneous Storage
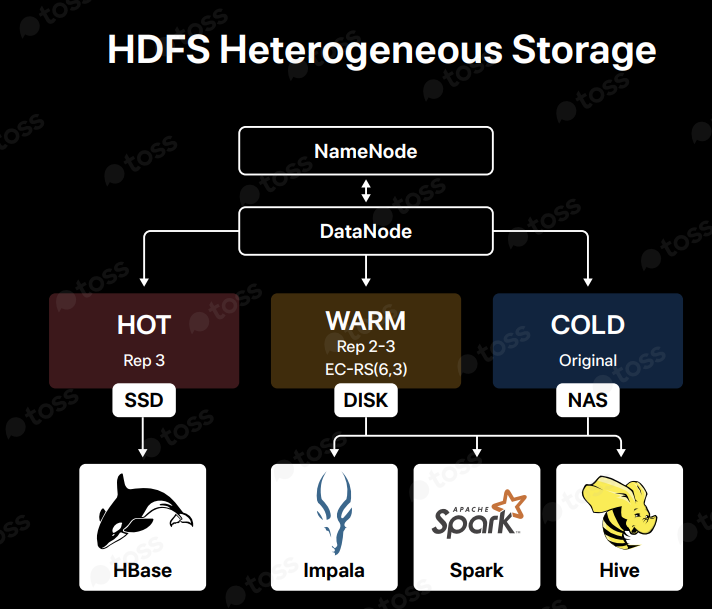
Heterogeneous Storage: 데이터의 접근 빈도와 중요도에 따라 서로 다른 유형의 storage(HOT, WARM, COLD)로 데이터 관리
WARM: ETL 영역에 활용됨
*ETL?
데이터를 추출(Extract), 변환(Transform), 적재(Load)하는 과정 또는 프로세스
3.1. 데이터 추출, 가공, 적재(ETL): 배치 프로세싱
impala, Spark, Hive를 활용
- EDA/ETL 시 impala 사용
multi-user performance & throughput 때문 / 성능이 좋았음 ㅋㅋ
- SQL 제한/복잡: Spark
- 처리 방식 다를 때 Hive 사용
<IMPALA>
(나중에 IMPALA 실습해봐도 좋을 것 같!)
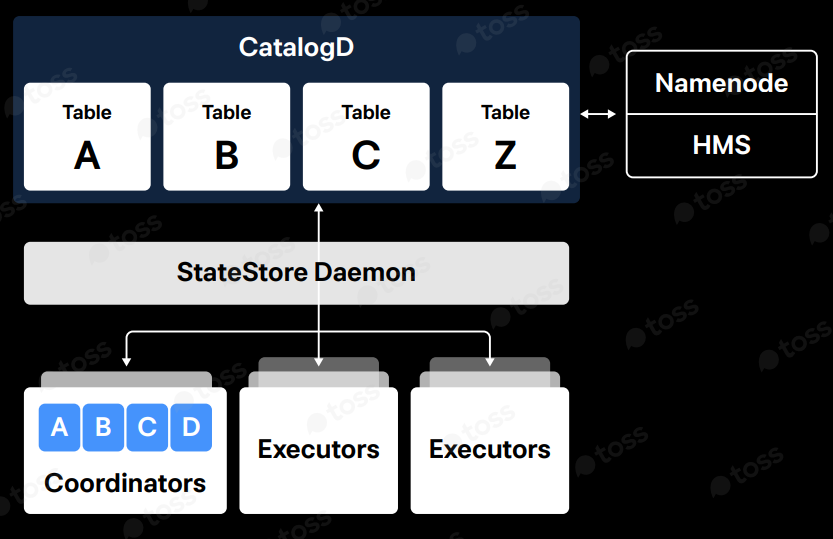
1. Catalog 서버
메타데이터를 캐시, 데이터 변경사항을 StateStore로 각 impala daemon(coordinator, executor)
- Impala의 한계
- graceful shutdown, query retry 미지원
- Impala v3.1 버전업, Airflow, Jenkins 활용
- 노드간 메타데이터 SYNC 필요
- SYNC_DOL Option
- MR, Spark, Hive 등 처리 시 Impala 메타데이터 SYNC 필요
- Workflow에 Invalidate Metadata 처리
- catalog, statestore -SPOF (Single Point of Failure)
- 컴포넌트간 리소스 간섭
- EDA, ETL Cluster (Active-Active) 분리 운영
- 매트릭 모니터링 및 운영의 어려움
- Impala Query Profile 수, Query Killer Long Run, Memory 과다 사용 Query Kill
- graceful shutdown, query retry 미지원
근데 생산성 및 속도가 빨라서 씀
(음 ~ 뭔 소리인지 하나도 모르겠다 ㅋㅋ 다음 학기에 무조건 데베개 들어야지 ㅠㅠ)
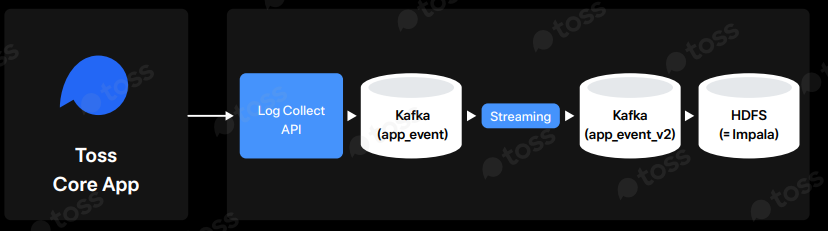
3.2. 데이터 추출, 가공, 적재(ETL): 리얼타임 프로세싱

4. 데이터 분석 : Query & Code 기반 데이터 분석
Jupyter나 Hue를 통해 ETL 도구에 접근하여 데이터를 분석 (데이터 분석가, 데이터 사이인티스트)
데이터 모니터링
실시한 서비스 현황 모니터링
이상 징후 감지 Alert by slack
- 메트릭을 수집하여 모니터링?
데이터 활용
실시간 데이터 - 스트리밍 처리
배치 데이터 - 서비스 애플리케이션에서 활용
토스 자체 개발 유저 분석 툴
- toss tuba
- toss analytics
(UI 뭐 어쩌고.)
화면 분석 tool - 로그 센터에서 화면 디자인 이미지 연동 : 화면 검색으로 결과 확인 가능
세그먼트 유저별로 화면 분석 가능
선버스트 분석 툴 kernel tree 구현
AB Test!! 내가 아는 거
두 가지 이상의 변형(A와 B)을 비교하여 어떤 것이 더 나은 성과를 내는지 실험적으로 검증하는 방법
토스 데이터 플랫폼
- 효율적인 데이터 인프라 설계
- 데이터 인프라 운영 자동화
- 데이터 분석 및 리포팅 자동화
데이터 흐름 설계 및 활용



