github 주소: https://github.com/Zhicaiwww/Diff-Mix
GitHub - Zhicaiwww/Diff-Mix: Official implementation of CVPR2024 paper "Enhance Image Classification via Inter-class Image Mixup
Official implementation of CVPR2024 paper "Enhance Image Classification via Inter-class Image Mixup with Diffusion Model"" - Zhicaiwww/Diff-Mix
github.com
an innovative inter-class data augmentation method known as Diff-Mix, which enriches the dataset by performing image translations between classes.
Diffusion-Mix model이 이미지의 클래스를 보존하면서 데이터 증강에 탁월한 효과를 보임.
연구 배경
문제상황: Text-to-Image(T2I) diffusion model이 이미지 생성에는 탁월하나, 이미지 분류에 효과적이지 못함.
→ Vanilla T2I: 특정 도메인을 잘 표현하지 못함(낮은 faithfulness).
→ Intra-class Augmentation (Da-fusion 등): original class를 너무 유지하려고 함(낮은 diversity).
목표: foreground의 faithfulness & background의 diversity
Diff - Mix
- fine-tuned diffusion model: Dreambooth(DB) + Textual Inversion(TI) + LoRA를 결합해 fine-grained(도메인 특화) 이미지를 잘 생성하도록 조정
- Inter-class Image Translation: 한 클래스 이미지 → 다른 클래스 프롬프트로 편집 → 배경 유지, foreground를 타깃 클래스에 맞게 변환. (같은 counterfactual 이미지 생성)
- Annotation 방식: 생성된 이미지를 단순 Mixup처럼 선형 보간하지 않고, diffusion의 비선형성을 반영해 라벨을 부여
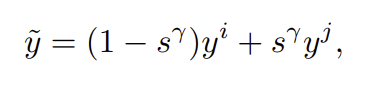
: 번역 강도
γ: 비선형 계수 (작을수록 타깃 클래스 쪽 가중)
실험
- Few-shot Classification (CUB dataset)
- Diff Mix, Diff-Gen (distillation), Diff-Aug (intra-class), Real-X (vanilla SD) → Diff Mix가 전반적으로 가장 높은 성능을 보임. 특히 shot 수가 적을수록(background 다양성이 부족할수록) Diff-Mix 효과 두드러짐.
- Conventional Classification (5개 dataset)
- Long-tail Classification (CUB-LT, Flower-LT)
- Background Robustness (Waterbird dataset-배경이 변형된 out of distribution(OOD) 데이터)
Ablation Study
- 데이터 크기: Synthetic data multiplier ↑ → 성능 지속적으로 ↑.
- 클래스 다양성: 참조 가능한 클래스 수 ↑ → 성능 ↑.
- Fine-tuning 전략:
- TI 단독 < DB 단독 < TI+DB 조합 (faithfulness & convergence 개선).
- Annotation γ 값:
- Few-shot → 작은 γ (타깃 클래스 confidence 높임).
- All-shot → 큰 γ (다양성 강조).
내 연구에 활용할 수 있는 포인트
- 데이터 부족 상황: 증강으로 해결
- Counterfactual 학습: 배경에 의존하지 않고 진짜 discriminative feature를 학습하게 유도
- 다른 도메인 확장: 논문은 bird/car/flower 등 fine-grained classification에 초점 → 의료 영상, anomaly detection 같은 특수 도메인에도 확장 가능
코드 리뷰
requirements.txt
torch==2.0.1+cu118
diffusers==0.25.1
transformers==4.36.2
datasets==2.16.1
accelerate==0.26.1
numpy==1.24.4- data
- pre-trained lora weights
- customized fine-tuning
- scripts/finetune.sh - perform fine-tuning on their own datasets. (DreamBooth, Textual Inversion 적용) → examples_per_class augmentation에서 {examples_per_class} shots으로 모델 파인 튜닝 가능. 4시간 정도 소요.
- construct synthetic data
- scripts/sample.sh : multi-processing 방법으로 증강된 데이터를 합성하는 script 제공.
- aug_samples/cub/diff-mix_-1_fixed_0.7 : output synthetic dir. 5-shot setting = aug_samples/cub/diff-mix_5_fixed_0.7
- Downstream classification
- scripts/classification.sh : synthetic data를 downstream classification에 통합. 위에서 샘플링 완료 후에.
'논문 리딩 > 전공 분야' 카테고리의 다른 글
| 네이버 D2 호텔 검색 서비스 (0) | 2026.02.28 |
|---|---|
| [CV] Segmentation and Feature Extraction of Fingernail Plate and Lunula Based on Deep Learning (3) | 2025.07.31 |
| [DL] Dataset of human skin and fingernails images for non-invasive-haemoglobin level assessment (0) | 2025.07.18 |
| [의생명데이터딥러닝] Deep Learning in Biomedical Data Science (1) | 2025.01.16 |
| [Toss 데이터] 토스 데이터의 흐름과 활용 (1) | 2025.01.16 |



